Explainability and its Role to Provide Benevolent Artificial Intelligence
Introduction

With the advent of the latest machine learning breakthrough, i.e., deep neural networks (DNNs), the inherent problem of explainability stands in front of the entire community as a barrier. Inspired by information processing and distributed communication nodes in human biological systems, artificial neural network (ANNs) methods have been proposed. Despite various differences from biological brains, ANNs methods particularly DNN have produced comparable results and in some cases surpass human expert performance in difficult fields such as computer vision, speech recognition, natural language processing, etc. However, the decisions that DNN models (i.e., machines) are making are not transparent and trustworthy to us (i.e., users). There has been various research during recent years to embody reasoning to machines (e.g., watch the video in Fig. 2).
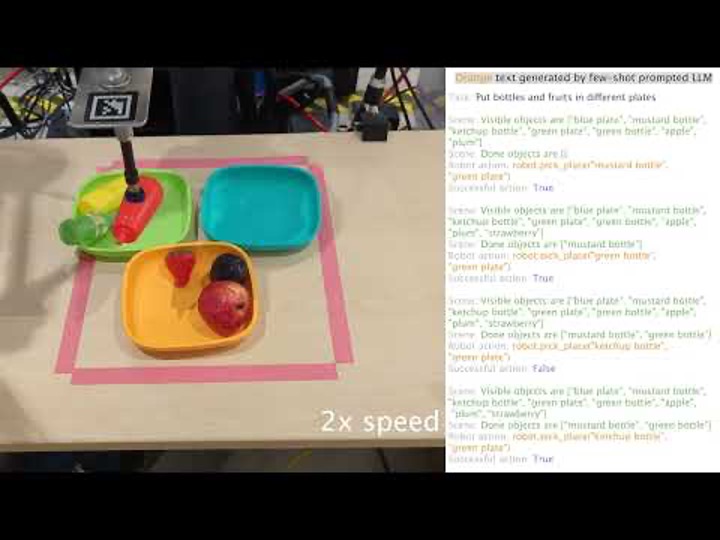
Fig. 2. Robotic reasoning through planning with language models
However, when it comes to life-changing decisions, such as disease diagnostics, an absolute level of trust is needed. Therefore, entrusting important decisions to a system that cannot explain itself presents obvious dangers.
What is the reason behind this opacity?
Before going any further, it is important to illuminate the difference between explainability, interpretability, and transparency that are being used to refer to a similar concept. Interpretability and explainability are often used interchangeably in the literature, but some papers make distinctions. In general, interpretation is the mapping of an abstract concept into a domain humans can understand, while explanation is the collection of features of the interpretable domain that have contributed to a given example to produce a decision. Transparency on the other hand is used as a synonym for model interpretability, that is some sense of understanding the working logic of the model.
There are different contributing factors that why ML decisions are unexplainable. On the one hand, it is claimed that unlike normal ML objective functions, it is hard to formalize and quantify the definition of criteria that are crucial for trust and acceptance. Trust-inducing criteria are ambiguous and need to be split into smaller, more specific concepts. From a technical perspective, considering DNN while a single linear transformation may be interpreted by looking at the weights from the input features to each of the output classes, multiple layers with non-linear interactions at every layer imply disentangling a super complicated nested structure which is a difficult task and potentially even a questionable one. On the other hand, the appearance of threats like adversarial examples has shown that maybe machine learning algorithms are not learning the way we expect it as they are working purely from observations and creating their own representations of the world. Besides, they might even learn something beyond our understanding. For instance, in terms of computer vision, despite efforts to create something similar, machine learning models are not working like human visual systems as they can be fooled by hardly perceptible adversarial artifacts.

The human cognitive system and learning process are not based on one sense only (e.g., the visual system). When a human child learns something, all his/her senses are involved as it’s not the case with training a machine. Therefore, the explanation that current machines can give for their decisions won’t be strong, while humans make justifications for their own decisions, without fully knowing the real functioning of their decision-making mechanisms. As a clear example, Fig. 3 demonstrates manipulated stop signs by physical adversarial attacks changing the decision of the ML model. Thus, this vulnerability can take a toll on someone’s life by deterring correct decisions on autonomous vehicles for instance.
Suggestions
Any solution should first consider not affecting the AI model’s accuracy, thus in AI in general and in ML specifically, often a tradeoff must be made between accuracy and explainability. In addition, explainability should not degrade the accuracy of ML models. If it’s inevitable, a trade-off should be maintained. There are some remarks claiming that making explainable AI systems is expensive in terms of both development and practice. Hence, it is important that explainability is added to applications where the cost of making a wrong prediction is high. Research on bridging the neural-symbolic gap for the integration of learning and reasoning would enable the automatic generation of interpretation, explanation, and reasoning. To this end, different approaches have been proposed. Many researchers support an approach to design ML algorithms that are inherently explainable. They simply believe that explainability is difficult because ML models are complex. Visualization is another approach that suggests depicting the representation of a DNN to find out the pattern of hidden units. Visualization techniques are essentially applied to supervised learning models, and popular visualization techniques include (i) Surrogate models, (ii) Partial Dependence Plot (PDP), and (ii) Individual Conditional Expectation (ICE). Knowledge extraction is another approach aiming to extract a comprehensible explanation from the network during training and encode it as an internal representation. Influence methods are the next type of XAI common approaches estimating the relevance of a feature by recording an ANN model’s behavior after changing inputs or internal components. In light of this, the sensitivity of the model’s decision to inputs, layer-wise relevance propagations, and quantifying feature importance are techniques that have been used. The final approach is the exampled-based explanation in which a particular sample from the database is selected and fed into the network to observe the behavior of the model. Unlike previous approaches, the exampled-based explanation is not interpreting the model by working on features or transforming the model.
Conclusion
Explainability has a subjective nature and depends mainly on what is explained and how the explanation is made. This represents a challenge that the explanation made by machines should be understandable to humans. Therefore, to simulate humans explanation and justification process, in addition to ML expertise XAI needs philosophy, psychology, and HCI skills to be involved. XAI has to resolve the lack of formalism in terms of problem formulation and clear unambiguous definitions. Maybe generating DNN models that can adopt these concepts and iteratively justify decisions from other networks would be the next practical step toward these aims. Although XAI is still in its infancy, there is no doubt that the security and privacy of humans facing the effect of fast-growing ML applications in their life depend on it.
References
Adadi, A., & Berrada, M. (2018). Peeking inside the black-box: a survey on explainable artificial intelligence (XAI). IEEE access, 6, 52138-52160.
Došilović, F. K., Brčić, M., & Hlupić, N. (2018, May). Explainable artificial intelligence: A survey. In 2018 41st International convention on information and communication technology, electronics and microelectronics (MIPRO) (pp. 0210-0215). IEEE.
Ghafourian, M., Fierrez, J., Gomez, L. F., Vera-Rodriguez, R., Morales, A., Rezgui, Z., & Veldhuis, R. (2023). Toward face biometric de-identification using adversarial examples. arXiv preprint arXiv:2302.03657.
This blogpost was written by Mahdi Ghafoorian.
